1.5 循环链表
大约 4 分钟
1.5 循环链表
1.5.1 循环链表的定义
循环链表:一般包括循环循环链表和循环循环链表,如下图所示
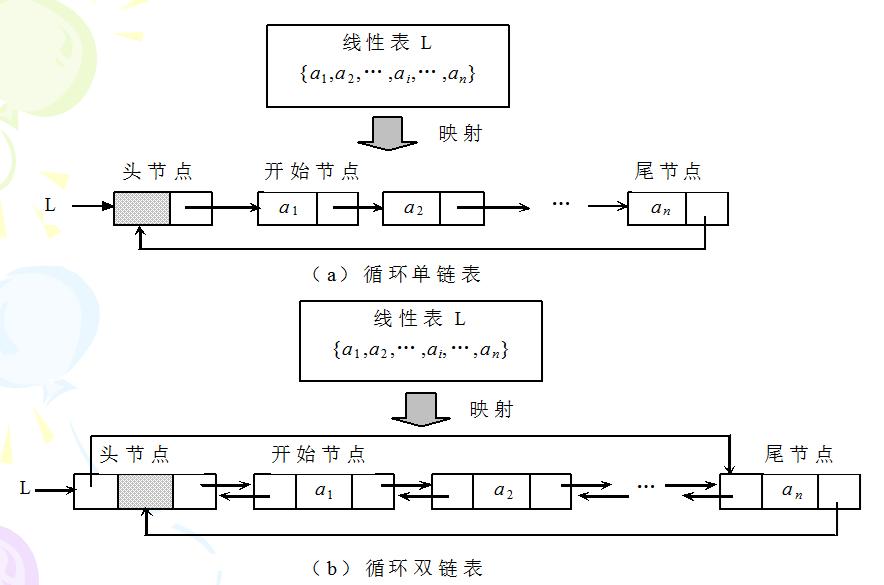
1.5.2 循环链表的实现方式
实现方式:不带头结点和带头结点,一般带头结点比不带头结点好
带头结点:写操作代码方便,一般用带头结点,不明确的都是带头结点的
不带头结点:写操作代码麻烦,要区分第一个数据和后续数据的处理
1.5.3 循环单链表上的操作(带头结点)
循环单链表的类型描述(与单链表一样)
typedef struct LNode{ //定义循环链表结点类型
int data; //数据域,可以是别的各种数据类型,本文统一用int类型
struct LNode *next; //指针域
}LNode, *LinkList;;
初始化和判空(与单链表不一样)
L->next = NULL改为L->next = L
//初始化
void InitList(LinkList &L){
L = (LNode *)malloc(sizeof(LinkList));
L->next = L;
}
//判空操作
bool Empty(LinkList L){
if(L->next == L){
return true;
}else{
return false;
}
}
判断表尾结点
//判断结点p是否是表尾结点
bool isTail(LinkList L){
if(p->next == L){
return true;
}else{
return false;
}
}
插入、删除
循环单链表的插入、删除算法与单链表几乎一样,不同的是如果在表尾进行,那么要让单链表继续保持循环的性质,即让尾结点的next域指向头结点。
时间复杂度=O(1)
查找
单链表的查找是从表头开始,找到表尾停止。而循环单链表中,若从表头开始查找,那与单链表的操作一致。若从表的任意位置开始查找,那么需要一个计数变量sum,当sum=表长时还未找到,则查找失败,退出循环。
求表长
与单链表一样
遍历
单链表只能从表头结点开始往后顺序遍历整个链表,循环单链表可以从表中的任意一个结点开始遍历整个链表。
1.5.4 循环双链表上的操作(带头结点)
循环链表的类型描述
typedef struct DNode{
int data; //数据域
struct DNode *prior,*next; //前驱和后继指针
}DNode, *DLinkList;
初始化和判空
L->next = NULL改为L->next = L
L->prior = NULL改为L->prior = L
//初始化
bool InitList(DLinkList &L){
L = (LNode *)malloc(sizeof(DLinkList));
if(L == NULL) return false;
L->prior = L;
L->next = L;
return true;
}
//判空操作
bool Empty(DLinkList L){
if(L->next == L){
return true;
}else{
return false;
}
}
判断表尾结点
//判断结点p是否是表尾结点
bool isTail(DLinkList L){
if(L->next == L){
return true;
}else{
return false;
}
}
插入
循环双链表的插入、删除算法与双链表几乎一样,不同的是如果在表尾进行,那么要让双链表继续保持循环的性质,即让尾结点的next域指向头结点,同时让头结点的prior域指向尾结点。
注:p->next->prior = s; 循环时不判断
时间复杂度=O(1)
//将x插入到循环链表L中*p结点的下一个结点
bool Insert(DNode *p, int x){
DNode *s = (DNode *)malloc(sizeof(DNode));
if(p == NULL||s==NULL) return false;
s->data = x;
s->next = p->next; //1
p->next->prior = s; //2
s->prior = p; //3
p->next = s; //4
return true;
}
//在循环链表L中*p结点后插入s结点
bool Insert(DNode *p, DNode *s){
s->next = p->next; //1
p->next->prior = s; //2
s->prior = p; //3
p->next = s; //4
return true;
}
删除
注:p->next->prior = s; 循环时不判断
按位序删除
时间复杂度=O(n)
//删除操作:将循环链表中的第i个结点删除
bool Delete(DLinkList &L, int i){
if(i<1 || i>Length(L)) return false;
DNode *p = GetElem(L,i-1);
DNode *q = p->next;
p->next = q->next; //1
q->next->prior = p; //2
free(q);
return true;
}
指定结点的删除
时间复杂度=O(1)
//删除操作:删除循环链表中的p结点的后继结点
void DeleteNextNode(DNode *p){
DNode *q = p->next;
p->next = q->next; //1
q->next->prior = p; //2
free(q);
}
查找(与单双链表完全一样)
按位查找
平均时间复杂度=O(n)
//按位查找:查找在循环链表L中第i个位置的结点
DNode *GetElem(DLinkList L, int i){
int j=0;
DNode *p = L;
if(i<0) return NULL;
while(p && j<i){
p = p->next;
j++;
}
return p; //如果i大于表长,p=NULL,直接返回p即可
}
按值查找
平均时间复杂度=O(n)
//按值查找:查找e在L中的位置
DNode *LocateElem(DLinkList L, int e){
DNode *p = L->next;
while(p && p->data != e){
p = p->next;
}
return p;
}
求表长、遍历、销毁
与单双链表一样